August 5th, 2023
Sentimental Analysis
Build a Serverless Sentimental Analysis app on AWS
Introduction
In today's landscape, gaining insights about a customer's sentiment has become increasingly crucial for making data-driven decisions. In this blog, we will build a sentimental analysis application on AWS. Sentimental analysis is about analysing a text and determining whether it's in a positive, neutral or negative tone. It can remove personal bias from product reviews, assisting organisations to make informed, objective decisions based on factual data rather than reading too much into the emotional aspect of it.
Overview of the architecture

AWS Lambda
AWS Lambda is a compute service that lets you run code without provisioning or managing servers. In the scope of this application, we will have two lambdas:
Producer Lambda
Its responsibility will be to write data to the Kinesis stream. In this case, we have hard-coded the data to some reviews about a shoe. In real-world scenarios, the origin of this data could be from various sources such as a web or mobile app.
Consumer Lambda
This lambda will be attached to the Kinesis stream as an event source and triggered whenever a new record is added. Upon invocation, it will perform a sentimental analysis using AWS Comprehend on the given input and then save the result to a DynamoDB table.
AWS Kinesis data stream
The Kinesis data stream will act as a real-time data ingestion pipeline, intaking data from the producer lambda, which the consumer lambda will read.
AWS Comprehend
AWS Comprehend will be used to perform Natural Language Processing (NLP) analysis to detect the sentiment of the data received from the stream.
AWS DynamoDB
To save the results from the analysis, we will use DynamoDB, which can then be consumed for further analysis and processing.
Prerequisites
Before building this application, you will need to meet the following criteria:
AWS account
To deploy this application, we will be using AWS. If you don’t have an account, you can get a free tier account from AWS' sign up page.
Node.js
Ensure you have nodejs installed on your machine with version 18. If not, you can download it from the Node.js website.
Terraform CLI
We will be using Terraform CLI to deploy the AWS resources, and you can download it from Terraform's download page.
Building the application
To deploy this application to AWS, we will be using Terraform.
Setup
Create a new file named main.tf in a directory, then run the following command to initialise Terraform:
terraform init
Provider
In the main.tf file, first, we will declare a provider block for AWS.
provider "aws" {
region = "ap-southeast-2"
}
You can replace “ap-southeast-2” with your desired AWS region.
Kinesis Data Stream
Next, let's create the Kinesis stream
resource "aws_kinesis_stream" "kinesis_stream" {
name = "sentimental-analysis-stream"
stream_mode_details {
stream_mode = "ON_DEMAND"
}
}
AWS offers two capacity modes for kinesis streams:
- On-Demand: With this, streams can automatically scale to handle gigabytes of data per second without planning for capacity. Also, to provide the required throughput, it automatically manages the shards.
- Provisioned: In contrast to the on-demand mode, it is required to specify the number of shards, and with that number, it calculates the throughput of the stream/ For our application, we will choose the On-Demand mode due to its simplicity and automatic scaling, reducing the operational overhead of managing shards and optimising costs by being billed only when it is used.
DynamoDB Table
To save the analysis result, we must create a DynamoDB table. Add the following blocks to your main.tf file:
resource "aws_dynamodb_table" "reviews_table" {
name = "reviews-sentimental-table"
hash_key = "id"
billing_mode = "PAY_PER_REQUEST"
attribute {
name = "id"
type = "S"
}
}
We will use the attribute id as our hash key in this table. This id will be a uuid generated by the consumer lambda.
Lambda functions
I am a big fan of the serverless framework when building Lambdas, as it makes it convenient to deploy them to AWS and offers a variety of plugins that improve the developer experience.
Sadly, it uses CloudFormation under the hood, and there isn’t a drop-in replacement for Terraform, but I found a good alternative, serverless.tf. It is a terraform module and handles the major pain points when using lambda with terraform, such as packaging it and building its dependencies, only deploying it when the hash has changed and performing complex deployments (canary, rollbacks).
Producer Lambda
module "producer_lambda_function" {
source = "terraform-aws-modules/lambda/aws"
version = "5.3.0"
function_name = "sentimental-analysis-producer-lambda"
handler = "index.handler"
runtime = "nodejs18.x"
environment_variables = {
"KINESIS_STREAM_NAME" = aws_kinesis_stream.stream.name
}
source_path = [
"${path.module}/../packages/producer/.esbuild"
]
attach_policy_statements = true
policy_statements = {
comprehend = {
effect = "Allow"
actions = ["kinesis:PutRecord", "kinesis:PutRecords"]
resources = [aws_kinesis_stream.stream.arn]
}
}
}
Notice how easy that was. Define the source path for your lambda, and it will handle the packaging for you.
Nonetheless, this block will create the lambda with a runtime of nodejs18.x . We have also added an environment variable about the name of the kinesis stream, which will be used by the kinesis client when writing records to the stream. To put the records in the stream, it needs a kinesis:PutRecords (no pun intended) IAM permission, which we have allowed in the policy_statements section.
Consumer Lambda
module "consumer_lambda_function" {
source = "terraform-aws-modules/lambda/aws"
version = "5.3.0"
function_name = "sentimental-analysis-consumer-lambda"
handler = "index.handler"
runtime = "nodejs18.x"
source_path = [
"${path.module}/../packages/consumer/.esbuild",
]
environment_variables = {
"DYNAMODB_TABLE_NAME" = aws_dynamodb_table.reviews_table.id
}
attach_policy_statements = true
policy_statements = {
kinesis = {
effect = "Allow"
actions = [
"kinesis:DescribeStream",
"kinesis:DescribeStreamSummary",
"kinesis:GetRecords",
"kinesis:GetShardIterator",
"kinesis:ListShards",
"kinesis:ListStreams",
"kinesis:SubscribeToShard"
]
resources = [aws_kinesis_stream.stream.arn]
}
comprehend = {
effect = "Allow"
actions = ["comprehend:BatchDetectSentiment"]
resources = ["*"]
}
dynamodb = {
effect = "Allow"
actions = ["dynamodb:BatchWriteItem"]
resources = [aws_dynamodb_table.reviews_table.arn]
}
}
}
This is similar to the consumer lambda, although its IAM permissions differ. On a high level, this lambda needs to call BatchDetectSentiment API on Comprehend and call the BatchWriteItem API on DynamoDB, and that’s it, but why do we have so many permissions for kinesis?
AWS states, “Lambda needs the following permissions to manage resources related to your Kinesis data stream”. For example, to read the data from the stream, a consumer needs a shard, which represents a position in the stream and allows the consumer to read from that stream. Hence, lambda needs to have permissions such as kinesis:GetShardIterator to consume the records from the stream.
Event source mapping
Finally, we must “connect” our consumer lambda with the kinesis stream. We will do so by setting an event source mapping between the kinesis stream and the lambda, triggering the lambda whenever data is inserted into the stream.
resource "aws_lambda_event_source_mapping" "consumer_lambda_source_mapping" {
event_source_arn = aws_kinesis_stream.stream.arn
function_name = module.consumer_lambda_function.lambda_function_name
starting_position = "LATEST"
}
Implementing the producer lambda
AWS provides a Kinesis client for nodejs through @aws-sdk/client-kinesis . We will use it’s PutRecordsCommand API to send the records to the kinesis data stream.
import { KinesisClient, PutRecordsCommand } from "@aws-sdk/client-kinesis";
import { v4 as uuid } from "uuid";
const kinesisClient = new KinesisClient({ region: "ap-southeast-2" });
const reviews = [
"these are some awesome shoes, a life save for me",
"My feet are swollen just after a couple of hours of use, would not recommend to anyone",
];
export async function handler() {
await kinesisClient.send(
new PutRecordsCommand({
StreamName: process.env.KINESIS_STREAM_NAME,
Records: reviews.map((review) => {
return {
Data: Buffer.from(JSON.stringify(review)),
PartitionKey: uuid(),
};
}),
})
);
}
Implementing the consumer lambda
The consumer lambda will be invoked once new records are created in the stream. To analyse the incoming records, it calls the BatchDetectSentimentCommand API on AWS Comprehend returns a sentiment (POSITIVE, NEGATIVE, NEUTRAL) and a score out of 1, indicating its confidence in its prediction.
Note that rather than calling the DetectSentimentCommand API for each record, we have used the batch command to save the number of API calls.
Once records have been analysed, it will save them to DynamoDB with a structure of:
{
"id": "string",
"text": "string",
"sentiment": "string",
"sentimentScore": "number"
}
The id will be a uuid randomly generated for each record, the text will be the raw input itself that the application will analyse, sentiment and sentimentScore will be the result returned from AWS Comprehend.
import {
BatchDetectSentimentCommand,
BatchDetectSentimentItemResult,
ComprehendClient,
SentimentScore,
} from "@aws-sdk/client-comprehend";
import {
BatchWriteItemCommand,
DynamoDBClient,
} from "@aws-sdk/client-dynamodb";
import { KinesisStreamEvent } from "aws-lambda";
import { v4 as uuid } from "uuid";
const comprehendClient = new ComprehendClient({
region: "ap-southeast-2",
});
const dynamoDbClient = new DynamoDBClient({ region: "ap-southeast-2" });
export async function handler(event: KinesisStreamEvent): Promise<void> {
const records = event.Records.map((record) =>
Buffer.from(record.kinesis.data, "base64").toString("utf-8")
);
const result = await comprehendClient.send(
new BatchDetectSentimentCommand({
TextList: records,
LanguageCode: "en",
})
);
if (!result.ResultList) {
throw new Error("Result from comprehend could not be retrieved");
}
const sentimentalResults = result.ResultList.filter(
(result) =>
typeof result.Index === "number" &&
result.Sentiment &&
result.SentimentScore
).map((value) => {
let result = value as Required<BatchDetectSentimentItemResult>;
return {
text: records[result.Index],
sentiment: result.Sentiment,
sentimentScore: result.SentimentScore,
};
});
const tableName = process.env.DYNAMODB_TABLE_NAME as string;
await dynamoDbClient.send(
new BatchWriteItemCommand({
RequestItems: {
[tableName]: sentimentalResults.map((sentimentalResult) => {
const loweredSentimentScoreKey =
sentimentalResult.sentiment.toLowerCase();
const sentimentScoreKey = (loweredSentimentScoreKey
.charAt(0)
.toUpperCase() +
loweredSentimentScoreKey.slice(1)) as keyof SentimentScore;
return {
PutRequest: {
Item: {
id: { S: uuid() },
text: { S: sentimentalResult.text },
sentiment: { S: sentimentalResult.sentiment },
sentimentScore: {
N: sentimentalResult.sentimentScore[
sentimentScoreKey
]!.toString(),
},
},
},
};
}),
},
})
);
}
Deploying the application
Now that we have completed the application code and the terraform, we can deploy it to AWS.
terraform apply
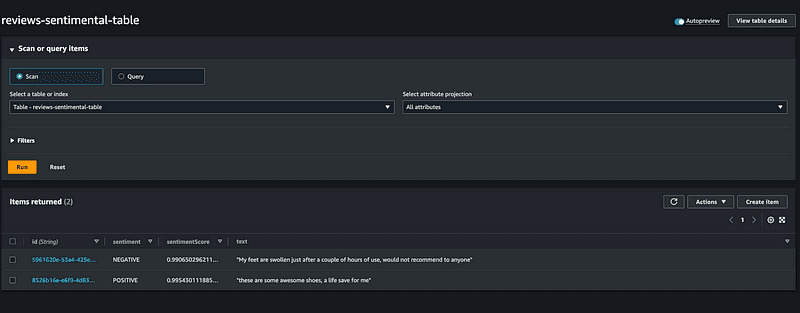
When Terraform has finished deploying your resources, you can start testing this application by invoking the producer lambda, which will insert the records in the Kinesis stream. Because the consumer lambda is set up as an event source to the stream, it should have got triggered and written the records to the DynamoDB. Finally, you can check the DynamoDB for the results, and I have attached a screenshot below; your output should like similar to this:
You can find the complete source code for this application on Github.
Conclusion
In this blog post, we built a sentimental analysis application using AWS Kinesis, Lambda, Comprehend and DynamoDB. With such serverless offerings, we created a scalable and cost-effective application.
This application can be extended for various use cases, such as improving customer service, where they can tailor their responses based on the mood of the conversation.
Thanks for reading this blog. Please feel free to reach out if you have any questions.